





Today we are announcing a jump in the QUALITY of our index, whilst also removing URLs which are SO bad, Google dropped them years ago. Over the last few months, people will have seen the size of our index increase dramatically and now we have got to the point where we need to look at whether to crawl faster… or just smarter.
Kudos to SEOMoz for building this into their model some time ago. We don’t intend to decrease our URL count to anything like the Moz index (at the time of writing they are reporting 89 billion URLs, whilst we are reporting 498 billion in our Fresh Index alone!) but with our index at this size, we have been able to identify huge amounts of URLs on domains that are just designed (it seems) to mess up crawlers.
We do not intend to show any comprehensive list of URLs we are excluding from our index (what would be the point of an index of de-indexed URLs?), but suffice to say that any URL that has merit should be exempt from this cull.
What did you Cull?
Here is an example:
http://tbod.asia did (in our previous index) have 9,157,905 URLs that we knew of. However – their value (and the value of the site) is such that even Google has dropped the whole domain:
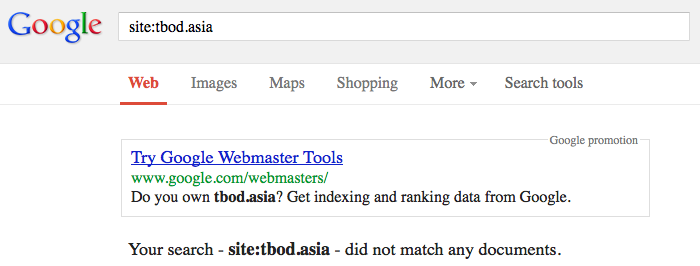
Unfortunately, the .asia TLD seems particularly affected by this mechanical spam and we only found these dropped pages (most likely) by crawling some of these internal pages themselves. Indeed – once the index has been culled, we we STILL index web pages on dropped domains that have even the remotest of merit.
Will this affect Penguin Investigations?
We do not believe so. The URLs we have discounted are not really different from session variables, in terms of value. Google are not penalizing these URLs per se. A cursory glance suggests they are dropping these URLs from their index (and most likely their crawl) as well. Believe it or not, there are a class of URLs that are even lower in value than those penalized by by Penguin. These URLs never get indexed… leave alone penalized… because Google wants to crawl smarter as well. Crawling the web is expensive to do – and being more efficient and smarter at it should be every crawler’s goal.
How many less links will I see to my site then?
Actually, for most people, none! To see a link TO your site, we need to have crawled the actual page. These are mostly URLs that we have seen exist, but there has never been any signal for us to get around to crawling these URLs.
Why Does This Change Make Majestic Better?
Quite simply – scale. Imagine what ELSE we can do for you if we free up the machines spent on crawling and indexing 150 billion URLs? That is about twice the size of SEOMoz’s entire index.
Taking these out will:
- Make everything else faster
- Allow us to look at collecting more data in the future
- Let us update Flow Metrics and our indexes more frequently
What if my site gets caught up in this change?
We have had one support request querying link count changes since the update, so if we get more then we can tweak this change. But we really don’t think it will affect most normal sites (including penguined sites) – but you are free to contact support and we will look at your site (but you’ll need to be specific). Nothing is irretrievable, but crawling smarter is a move towards a better tool set.
- How Important will Backlinks be in 2023? - February 20, 2023
- What is in a Link? - October 25, 2022
- An Interview with… Ash Nallawalla - August 23, 2022
I am quite happy that you guys decided to improve the overall quality of your index — Whenever I comb through link profiles, I see alot of de-indexed links. That being said, you guys pride yourself on having the largest, most comprehensive database. This is one of the reason I am a strong supporter of you guys over the competitors. But how does updating your crawler impact this? Are you no longer focusing on the size of your index? (In any case, I put my faith in you guys, you’re updates have been excellent thus far. I assume you know what you’re doing.)
May 6, 2013 at 9:36 amOur crawler has been updated few months ago and it works a lot better now – we crawl important pages much quicker than before.
Size of our index is still very large – the removals of URLs were very targeted, that’s not the same as removing backlinks – almost all removes URLs were NOT crawled and therefore could not have been source of backlinks.
May 6, 2013 at 5:12 pmThanks for taking the time to explain this update to your services. When I’m checking links, I don’t care to know about every single one that goes to my site. My main reason for checking is simply to see what my top few hundred links are so that I can make sure to keep working on only those sources that are legitimate and are actually helping my campaign. So these changes won’t affect my experience at Majestic at all.
May 6, 2013 at 9:01 pmA lot of URLs I have discounted are not really and really different from session variables, in terms of value. It is said that Google are not penalizing these URLs per se. A cursory glance suggests they are dropping these URLs from their index
May 7, 2013 at 10:49 am… or dropping them BEFORE the crawl itself. This is more efficient and Google is all about being efficient.
May 7, 2013 at 1:56 pmThe fresh index sites are a great way to search bad link site.. Carry on your innovation in majestic seo..
Thanks to all webmasters who involve in doing this such a good tool.
Regards,
May 28, 2013 at 10:47 amJuli Galetti